
根據 9 月 11 日跑分數據,NVIDIA 旗下新一代超級晶片 GH200 表現亮眼,在各個測試項目上都相較 H100 至少有 15%左右的提升。
(前情提要:Nvidia的AI晶片H100有多神?為何一片難求?)
(背景補充:Tether斥資4.2億鎂買ㄧ萬個「Nvidia H100」:合作礦企出租算力給AI新創)
生成式 AI 的運算需求不斷增長,助推 GPU 大廠輝達(Nvidia)股價大漲再創新高。而在 8 月中,Nvidia 執行長黃仁勳在展覽中再次力推 DGX GH200,這是一款採用 Grace Hopper 加速運算卡所打造的新一代生成式 AI 超級晶片,也是 Nvidia 首款 Exaflop 等級的 DGX 超級電腦產品。
延伸閱讀:Nvidia黃仁勳搞革命「GPU效能5年千倍」,亮相AI超級電腦、晶片:打破摩爾定律
性能輾壓 H100 17%
根據 9 月 11 日跑分數據,NVIDIA 宣布旗下 NVIDIA GH200 、 NVIDIA H100 、 NVIDIA L4 GPU 與 Jetson Orin 在同類產品中都獲得領先的表現。
其中 NVIDIA GH200 在首次提交單一晶片上,與單張 H100 配合英特爾 CPU 相互比較後,GH200 的組合,在各個測試項目上都至少有 15%左右的提升。Nvidia 人工智慧總監 Dave Salvator 在新聞發佈會上表示:
Grace Hopper 的首次表現非常強勁,與我們提交的 H100 GPU 相比,性能提高了 17%,而我們已經在產業內全面領先。

GH200 是什麼?
據官方說明,NVIDIA GH200 是首個將 NVIDIA 的 H100 GPU 和 Grace CPU 整合在一起的超級晶片,這兩者之間再通過頻寬高達 900GB/s 的 NVLink-C2C 連互連接,能提供更好的擴充性,以超快速度進行深度學習訓練。
簡單來說 GH200 就是記憶體容量更大,頻寬也更大,並且能自動調節在 CPU 和 GPU 之間自電力,增加整體效能表現。
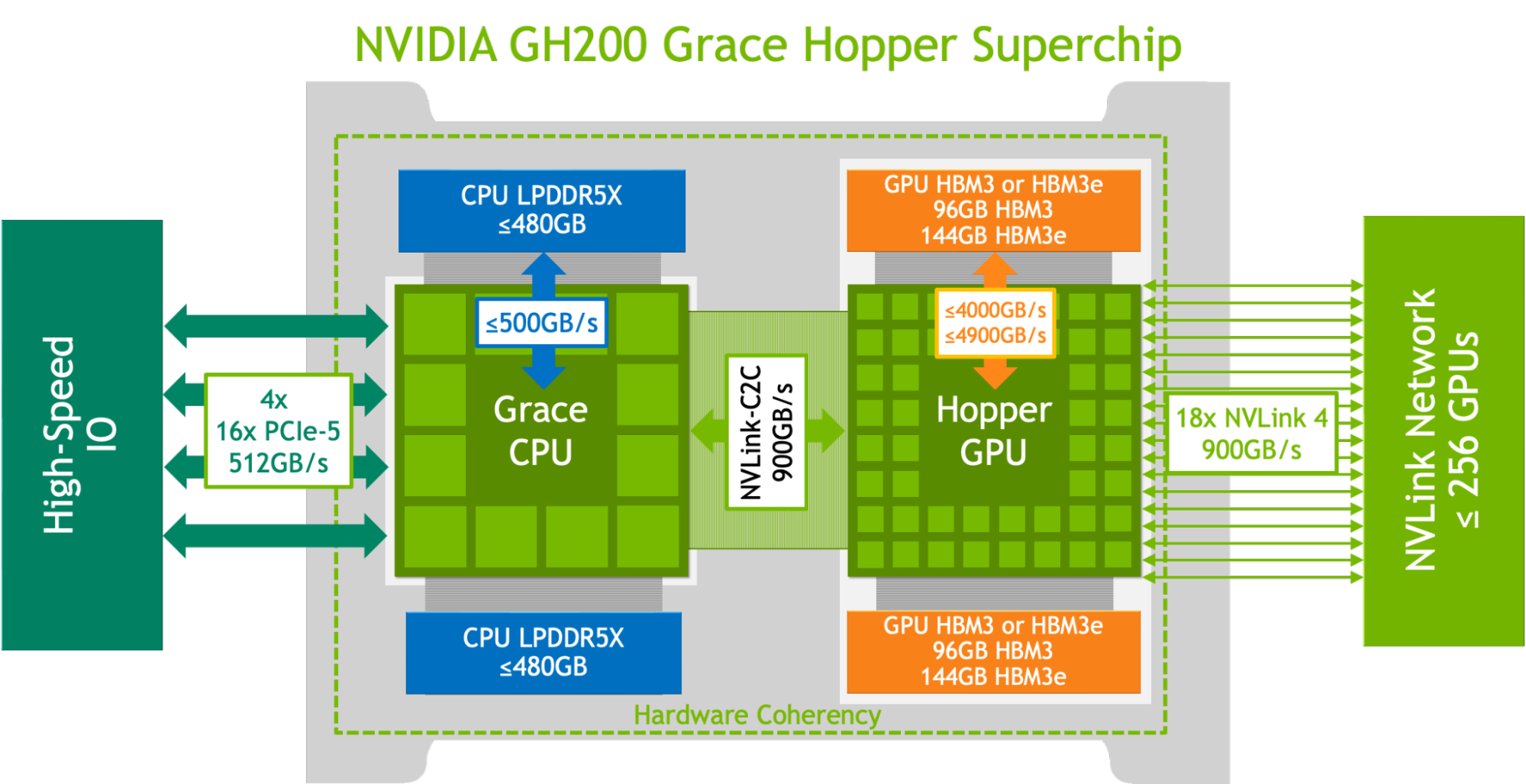
NVIDIA 表示 GH200 有三大特點:
-
適用於大型模型的龐大記憶體:為開發人員提供將近超過 500 倍的記憶體來打造大型模型。
- 超節能運算:將頻寬提升 7 倍,並將互連功耗降低 5 倍以上。
-
已整合且可立即執行:數週內即可打造大型模型

多數選手性能比上一代提升至 20%
在 2023 年 5 月的 Computex 期間,NVIDIA 的 CEO 黃仁勳提到了 GH200 晶片預計在 2024 年第二季度量產。值得一提的是,在 MLPerf v3.1 基準測試中,有超過 13,500 個結果,其中不少提交者的性能比 3.0 基準提高了20%以上。
其他提交者包括華碩,Azure,Connect Tech,DELL,富士通,Giga Computing,Google,H3C,HPE,IEI,Intel,Intel Habana Labs,Nutanix,甲骨文,高通,Quanta Cloud Technology,SiMA,Supermicro,TTA 和 xFusion等。


📍相關報導📍
AI大未來!這6個加密專案加入了 NVIDIA Inception 計劃




{kind=link}